Volume 5: I'm No Spielberg
Hey everyone!
This week, we’re unpacking how AI actually understands meaning. In AI Education, we explore vectors & embeddings — how models convert language into numbers that carry context, power smarter decisions, and even help categorize spending in your budget.
Then, in our 10-Minute Win, we’ll apply structure to action with a fast stock research workflow using Perplexity AI — a practical way to turn information overload into clarity.
And in Founder’s Corner, I’m sharing what it’s really like learning to build AI-driven video and image content from scratch — the failed takes, creative ceilings, and the systems I’m using to turn each experiment into progress.
Thank you for following along and growing with me each week as we keep turning AI theory into practice. Let's dive in with your curated AI news from the past week.
Missed a previous newsletter (released every Tuesday at 9AM EST)? No worries, you can find them on the Archive page at MindOverMoney.ai. Don’t forget to check out the Prompt Library, where I give you templates to use in your AI journey. If you have content suggestions, a workflow idea, or want to share a success from your AI journey, reach out at admin@mindovermoney.ai.
Signals Over Noise
We scan the noise so you don’t have to — top 5 stories to keep you sharp
1) Microsoft’s big Copilot rollouts: Groups, “real talk,” memory & Mico
Summary: Microsoft pushed a bundle of Copilot updates—Copilot Groups (up to 32 people in one AI chat), an optional “real talk” mode that challenges shaky assumptions, expanded memory controls, and Mico, a playful voice avatar.
Why it matters: Assistants are getting more social, context-aware, and agent-like—upgrades everyday users will actually feel across planning, research, and team workflows.
2) OpenAI launches the ChatGPT “Atlas” browser
Summary: OpenAI debuted Atlas, a desktop browser with ChatGPT built-in and an “agent mode” that can proactively browse and summarize the web.
Why it matters: If AI-first browsing sticks, expect a shift from “search → click links” to “ask → get answers (with sources)”—changing how readers, researchers, and marketers reach information.
3) Poll: Americans are worried about AI’s energy & water use
Summary: A new AP-NORC / EPIC survey finds broad concern about AI’s environmental impact from data centers, with strong support for safeguards.
Why it matters: Compute demand = policy pressure. Expect more scrutiny on where data centers get built and how providers curb environmental costs.
4) Federal judge admits staff used AI to draft a flawed court order
Summary: Mississippi Judge Henry Wingate acknowledged a staffer used AI in drafting an order that was later withdrawn—fueling a judiciary review of AI use.
Why it matters: Governance is catching up to AI—more institutions will set clear rules and disclosure for AI-assisted work in high-stakes settings.
5) GM is bringing a Google Gemini-powered assistant to cars in 2026
Summary: GM will add a conversational Google Gemini assistant across many 2026 model-year cars, trucks, and SUVs—tightly integrated with Google services and designed for hands-free help on the road.
Why it matters: Car UIs are becoming AI-native. Expect safer voice-first controls, better navigation and scheduling, and new developer surfaces inside vehicles—useful for consumers and brands alike.
AI Education for You
Vectors & Embeddings 101: How AI Represents Meaning
So far we climbed the ladder—artificial intelligence → machine learning → deep learning—peeked into neural networks, learned how models use features and labels with fair splits, and saw why data shape and quality matter.
Now we answer a key “how” question: How do modern systems represent meaning so they can understand and produce language? The answer is vectors and embeddings.
- A vector is a list of numbers.
- An embedding is a special vector that captures meaning from text or other content.
Why this matters for artificial intelligence and models like ChatGPT:
- Understanding: Models do not learn from raw words. They learn from numbers. Embeddings turn words, sentences, and documents into numbers that carry meaning.
- Learning patterns: During training, the model adjusts these numbers so that things with similar meaning end up close together. This helps it learn stable patterns in language.
- Writing answers: When the model generates text, it uses these meaning-rich numbers to choose the next word that fits the context. That is why replies can sound natural and stay on topic.
- Finding useful context: Many systems compare embeddings to look up the most relevant text (for example, the right part of a long bank statement), then let the model read it and answer with better facts.
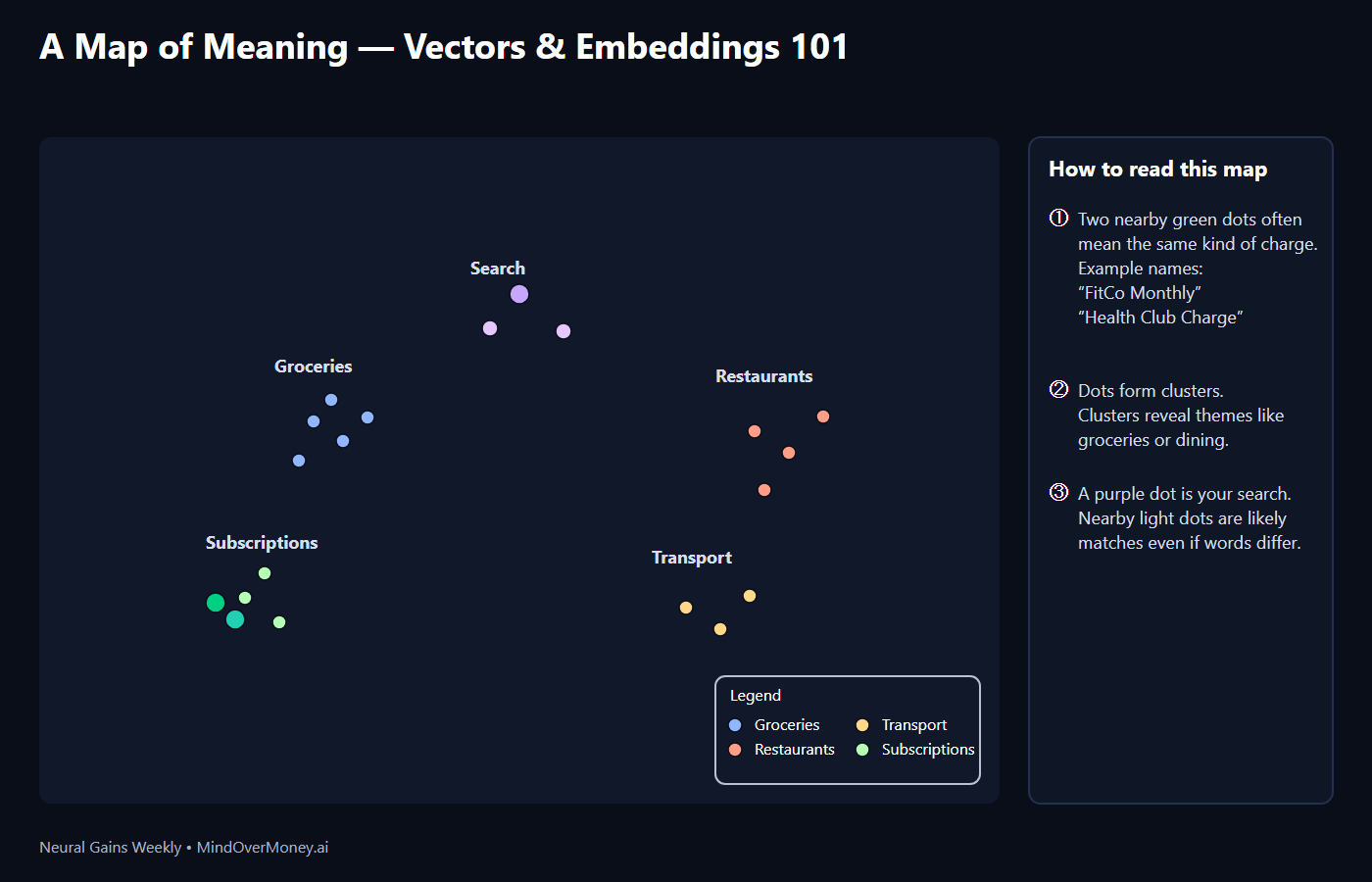
Think of embeddings as dots on a map of meaning. Dots that are close often talk about the same thing, even if the words differ. That simple idea explains everyday magic: grouping similar purchases, spotting recurring charges with slightly different names, and searching receipts in plain words. Understanding this map helps you see how modern artificial intelligence understands language—and why clean, readable data still makes all the difference.
Vectors & Embeddings in plain English
1) Vector: A vector is just a list of numbers. For example: [0.12, -0.07, 0.55, …]. Alone, that list is not helpful. It becomes useful when the numbers capture meaning.
2) Embedding: An embedding is a meaningful vector created from text or other content. The rule of thumb: similar things → similar vectors. If your content is a document or receipt, it first needs to be turned into readable text; then that text can be represented as an embedding.
3) Closeness = similarity: Picture a map of meaning. Each item is a dot.
- Close dots often mean similar items (groceries near groceries; restaurants near restaurants).
- Far dots often mean different items.
4) Why this matters in an everyday budget:
- Group look-alike spending without reading every line.
- Spot recurring charges even when names vary.
- Search receipts in plain words and still find related lines.
5) How vectors and embeddings help models learn:
- They turn words into numbers the model can learn from.
- They make patterns easier to see: close dots are easier to separate into useful groups (for example, groceries versus restaurants) or to predict a label (for example, “subscription” versus “not subscription”).
- They support learning with labels (predict a category) and without labels (discover clusters).
- They help systems retrieve context before writing, by finding nearby dots in the meaning space.
Examples that land
1) Catch subscriptions with varied names:
- Charges: “FitCo Monthly” and “Health Club Charge.”
- The words differ. The meaning is the same.
- On the map, these charges sit near each other, helping the app flag them as recurring.
2) See trends by grouping similar spend:
- Grocery stores form one cluster. Restaurants form another.
- A quick glance shows “eating out grew this month” without scanning every line.
3) Search receipts in everyday words:
- You type “school supplies.”
- The app finds lines like “notebooks, pencils, markers.”
- Those lines sit near your words in meaning, even without the exact match.
One-screen recap — Vectors & Embeddings 101
- A vector is a list of numbers.
- An embedding is a meaningful vector built from text or other data.
- Closer on the map = more similar in meaning.
- This powers grouping, subscription spotting, plain-word search, and easier learning from your data.
- Clean, readable input still matters for good results.
Your 10-Minute Win
A step-by-step workflow you can use immediately
🔎 Stock Research Assistant with Perplexity AI
Why this matters: Stock research can feel endless. In ~10 minutes, you can grab official docs (10-K/10-Q, earnings PR), drop them into Perplexity’s free plan, and get a clean, sourced brief: business snapshot, recent catalysts, risks, and follow-ups — with clickable citations to verify.
Step 1 — Pick a ticker & define your question (1 minute):
Choose any publicly traded company (e.g., AAPL, MSFT, NVDA). Write one guiding question to focus the AI, such as:
- “How sustainable is revenue growth over the next 12 months?”
- “What are the top 3 risks management is signaling?”
- “What changed since last quarter’s results?”
Step 2 — Open the official sources (3–4 minutes):
You’ll rely on free primary sources (most accurate):
- SEC EDGAR (Free): search the company → open the latest 10-Q / 10-K and any recent 8-K (earnings release). Use Full-Text or Company search.
- Investor Relations (IR) site (Free): find the latest earnings press release and presentation under Investors → News/Events/Press Releases.
Why these: EDGAR filings and issuer PRs are free and authoritative; they’re the source of truth you can verify anytime.
Step 3 — Use Perplexity (Free) to build a sourced brief (3–4 minutes):
Perplexity’s free tier returns answers with source links/citations by default, which is perfect for research.
Open perplexity.ai → new thread → paste the prompt below.
🧠 Copy + Paste Prompt (works for any ticker)
You are my AI equity research assistant.
Goal:
Create a concise, sourced research brief for the following ticker(s): <TICKER(S)>. Focus on what changed recently and what to watch next.
Use only primary/official materials:
- Latest 10-Q or 10-K on SEC EDGAR
- Most recent earnings press release and/or 8-K (IR site or EDGAR)
- Recent investor presentation (IR)
If needed, include 1–2 reputable news sources only to clarify context (no blogs). Every claim must have a citation.
Deliverables (use headings + bullets):
1) Business Snapshot — what the company sells, key segments/geographies.
2) Recent Results & Guidance — revenue, EPS (GAAP/non-GAAP if stated), YoY, margin notes; highlight changes vs prior quarter/year.
3) Catalysts (next 1–2 quarters) — product launches, regulatory, macro, seasonality; cite sources.
4) Key Risks — supply, competition, pricing, FX, customer concentration; cite sources.
5) Management Signals — 1–2 short quotes with speaker + source link.
6) Watchlist for Next Quarter — 3 follow-up questions.
7) Source Table — list each source with title + link (SEC form type if applicable).
Rules:
- Include inline citations next to each factual bullet.
- If a number is not disclosed, say “not disclosed” rather than estimate.
- Prefer issuer filings/IR over secondary sources.
- Keep it to ~250–350 words total.
Tip: If Perplexity includes unsourced lines, reply: “Re-run with citations on every numeric claim and links to EDGAR or IR.”
Step 4 — Add a quick KPI table (1–2 minutes):
Ask Perplexity in the same thread:
“Append a 6-row table: Metric | Current | Prev Q | YoY | Source link for Revenue, EPS, Gross Margin, FCF (if disclosed), Key Segment metric, and one Operating KPI. Cite each cell.”
Then:
“Export that table as CSV so I can paste into Google Sheets.”
The Payoff
In ~10 minutes you’ll have a sourced, skimmable brief and a KPI table you can reuse next quarter — with links back to the filings so you (or your readers) can verify in one click.
💡 Pro tip: Save each brief to a ticker folder. Next quarter, ask Perplexity: “What changed since the last brief on <TICKER>? Link to new filings only.”
Transparency & Notes for Readers
- Perplexity cost: A Standard (Free) plan exists; paid tiers (Pro/Max) just expand limits and models. This workflow works on the free plan.
- Source quality: Perplexity is an answer engine with citations; still verify numbers by clicking the EDGAR/IR links it provides.
- Primary sources: SEC EDGAR and issuer IR are free and should be your first stop.
- Education, not advice: Use this to learn faster and track what matters; it’s not investment advice.
Founder's Corner
Real world learnings as I build, succeed, and fail
"It does not matter how slowly you go as long as you do not stop." — Confucius. This quote embodies my AI journey up to this point, especially when it comes to AI image & video generation. The models and features released over the past 6 months have been groundbreaking, leading to a new wave of creative possibilities. And for me, this was exciting and timely, as I thought building visuals and marketing videos for Neural Gains Weekly would be an easy win. I quickly realized that I entered into another realm of AI education, one filled with failures, hidden costs, unique context, and educational opportunities.
The principle of slow and steady progress applies to AI, affirming that consistent, patient effort will lead to growth and quality over time. I’m very much working to better understand how to maximize efficiency and output of AI tools to help grow my audience. I’m currently using 3 tools to build video content and images used on the website and social media: HeyGen, Veo (inside Gemini), and NanoBanana. Through trial and error, I’m starting to learn how to interact with these tools to create better content. And I want to share a few lessons with you in real time as I continue to iterate and build.
Lesson 1: Costs & caps shape creativity
I hit the ceiling fast. HeyGen’s free plan gives you 3 videos per month, perfect for a taste test, but not rapid iteration. Inside Gemini, I kept hitting Veo's daily caps (typically ~3–5 clips depending on mode/plan), which meant I had to get the output perfect in one or two tries. These limits don’t just slow output; they fragment learning. It’s difficult to refine your skills when the ability to tweak small aspects of the output is taken away.
Takeaway: Treat free credits like film stock—plan your shots, batch your tries, and use them where learning compounds fastest.
Lesson 2: Video/image prompts aren’t chat prompts
I’m used to using AI as a strategic partner and interacting in a structured, conversational manner. Video and image prompts are different and require a nuanced approach to bring your vision to life. I’ve struggled to bridge that gap and deliver useful content to help market Neural Gains Weekly, as only about 10% of my videos have actually made it to social media.
The failure is teaching me what I need to learn next: video/image models don’t want paragraphs, they want a director. They need detailed information and context to build the scene. Sounds easy, but take it from me, this process takes time to master.
Here’s a few concepts I’m working to incorporate into content creation journey:
- Story first, one beat at a time: define one subject + one action for 5–8 seconds.
- Name the shot & camera: wide/medium/close-up, tripod or slow dolly.
- Lock the look: 3–5 words I’ll reuse (e.g., “soft daylight, shallow depth”).
- Add constraints: what must not change (no text overlays, tripod, centered subject).
- Iterate on one variable: if a take is close, tweak only camera or lighting—not both.
Takeaway: Treat prompts like stage directions—specify shot, one beat, look, and a constraint, then iterate one variable at a time so your learning compounds fast.
Lesson 3: Power needs pre-visualization
The models are intuitive, but they can’t read my mind. I kept expecting the model to “see” what I saw. It didn’t. Without a clearly named look in my head, the results drifted—skin tones shifted, framing wandered, and every retry felt unrelated to the last. That failure taught me the third lesson, pre-visualization is part of the work. I had to take ownership and start articulating the look I was chasing in a way the model could understand. This was and continues to be a difficult shift since I have no background in producing, editing or filming videos. It’s essentially learning a new language with outputs as the main measurement of progress. I’m still practicing, but the learning is clear: the model follows the visual story I’m able to describe consistently.
Takeaway: Name the look you’re chasing, then keep naming it—so each attempt teaches you whether you’re getting closer, not just different.
What’s Next:
I’m keeping experiments simple and repeatable: storyboard first, draft short, refine with the style kit, while focusing on the vision. Keep an eye out on my Socials to see progress as I continue to iterate and learn on the fly.
Goals & Milestones:
Follow us on social media and share Neural Gains Weekly with your network to help grow our community of ‘AI doers’. You can also contact me directly at admin@mindovermoney.ai or connect with me on LinkedIn.